NL2SQL Workflow System
NL2SQL Workflow System is an LLM-assisted data analysis app that turns plain-English questions into SQL for SQLite, CSV, and Excel data sources. It validates schemas, generates and refines SQL, executes read-only queries safely, explains the results, and can produce chart code when visual output is useful.
Problem Statement
Non-technical users often want answers from structured data without learning SQL, understanding schema details, or manually writing queries. At the same time, naïve text-to-SQL tools can generate invalid, unsafe, or misleading queries when values and column names do not exactly match the dataset.
This project addresses that gap by combining schema extraction, LLM generation, value matching, SQL refinement, safe execution, and result explanation in one workflow.
Solution
I built a Streamlit application that guides the user from question to answer through a staged workflow. The app reads the uploaded file, builds schema context, asks the LLM for SQL, improves the query using fuzzy value matching, runs the final statement safely, and then summarizes the output in plain language.
- Schema ingestion for SQLite, CSV, and Excel inputs
- LLM-based SQL generation from natural-language questions
- Entity extraction and fuzzy value matching for better query accuracy
- Read-only execution, result analysis, and chart generation
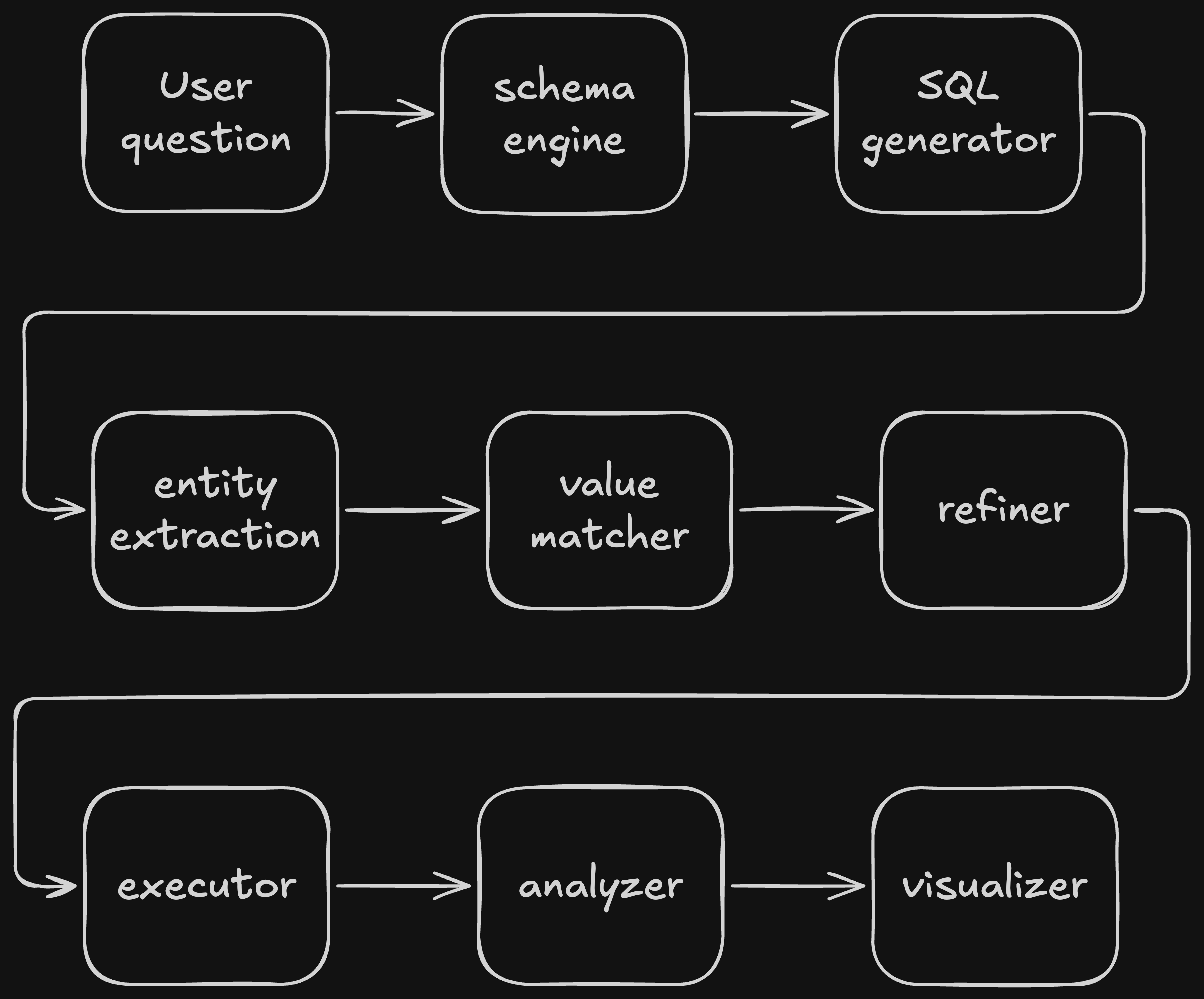
System Architecture
The system is organized as a pipeline so each step has a clear responsibility. That separation makes the workflow easier to debug, extend, and explain.
Technical Implementation
UI and Workflow
The UI is implemented in Streamlit so the workflow stays simple and interactive. The user can upload a file, enter an API key, ask a question, and inspect each stage of the pipeline without leaving the page.
# High-level workflow
file -> schema extraction -> prompt assembly -> SQL generation
-> value matching -> SQL refinement -> safe execution
-> result table -> LLM summary -> chart code generationEngine Modules
The core logic is split into focused modules under the engine folder. Each module handles one stage of the workflow, which keeps the codebase easier to maintain and easier to test.
- schema_engine.py: reads uploaded files and extracts table structure
- generator.py: asks the LLM to generate SQL from question + schema
- entity_extractor.py: identifies table, column, and value references
- value_matcher.py and utils/search.py: find close matches for values
- refiner.py: rewrites SQL with matched values when needed
- executor.py: runs read-only SQL and returns rows
- analyzer.py and visualizer.py: summarize results and create chart code
Safety and Validation
The executor is designed for read-only analysis so the app does not modify the source data. The workflow also tries to correct mismatched literals before execution, which makes the final SQL more robust against imperfect LLM output.
Data Flow
Data flows from the uploaded source into schema extraction, then into prompt building for the LLM, then through query refinement and execution, and finally into the result table, natural-language summary, and optional chart output.

Challenges & Solutions
Challenge 1: Inexact values in LLM-generated SQL
LLMs often produce valid-looking SQL with incorrect literal values or slightly wrong column references.
Solution: Added entity extraction and fuzzy matching so the workflow can map user intent to the nearest values in the dataset before execution.
Challenge 2: Safe execution of generated SQL
Generated queries must not modify the source data or access unsupported operations.
Solution: Restricted execution to read-only analysis queries and organized the app so each stage can be inspected before the final query runs.
Key Learnings
- Learned how to structure a multi-step LLM workflow instead of a single prompt call
- Improved my understanding of schema extraction and SQL generation pitfalls
- Practiced fuzzy matching and value normalization for messy real-world data
- Gained experience designing a safe, read-only query pipeline
- Understood how to connect analysis, explanation, and visualization in one app
Future Improvements
- Add support for more file formats and larger datasets
- Improve chart selection with automatic visualization recommendations
- Add stronger SQL validation and error recovery
- Support multiple LLM providers and prompt strategies
- Add caching and test coverage for the workflow modules