Recently I spent some time trying to understand what actually happens inside a large language model (LLM). At first, it looked like magic, but after digging deeper, I realised that the core idea is surprisingly simple.
An LLM (Large Language Model) is essentially a very large neural network trained on huge amounts of text data. During training, it reads billions or even trillions of words collected from books, articles, websites, code repositories, research papers, and many other sources.
The goal of the model is simple:
Predict the next token given all previous tokens.
Everything else emerges from this objective.
The Basic Idea
Imagine I give the model the sentence:
The capital of France is
The model does not search the internet for the answer. Instead, based on patterns learned during training, it calculates probabilities for possible next tokens.
Something like:

The model then selects a token based on these probabilities.
After generating "Paris", it repeats the same process for the next token.
Input:
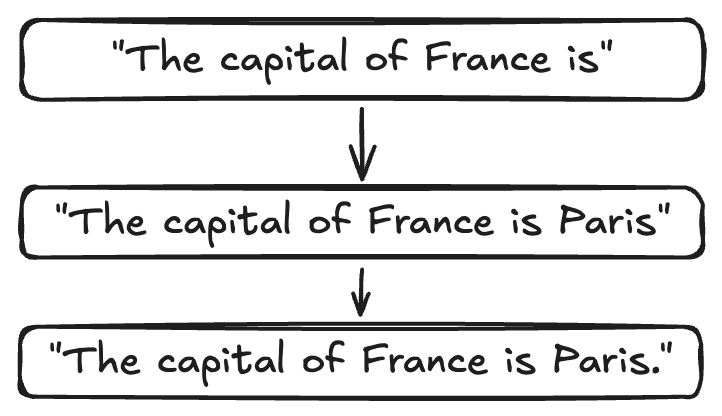
Generation is simply this prediction process repeated over and over.
Why Neural Networks Need Training
An LLM is made up of billions of parameters (often called weights). These weights determine how information flows through the network. Initially, the weights are random, and the model produces nonsense.
During training:
- The model predicts the next token.
- The prediction is compared with the actual token.
- The error is calculated.
- The weights are adjusted slightly.
- The process repeats billions of times.
Over time, the network gradually learns:
- grammar
- sentence structure
- facts
- reasoning patterns
- coding syntax
- language relationships
This learning process is done using optimisation algorithms such as gradient descent and backpropagation.
The First Problem: Computers Do Not Understand Words
Computers do not understand English the way humans do. To a computer, words such as 'cat', 'dog', 'apple', or 'happy' are simply sequences of characters with no inherent meaning. It does not naturally know that 'cat' and 'dog' are related animals, that 'happy' and 'joyful' have similar meanings, or that 'good' and 'bad' are opposites. To make language understandable to a neural network, we need a way to represent the meaning and relationships between words mathematically.
Word Embeddings
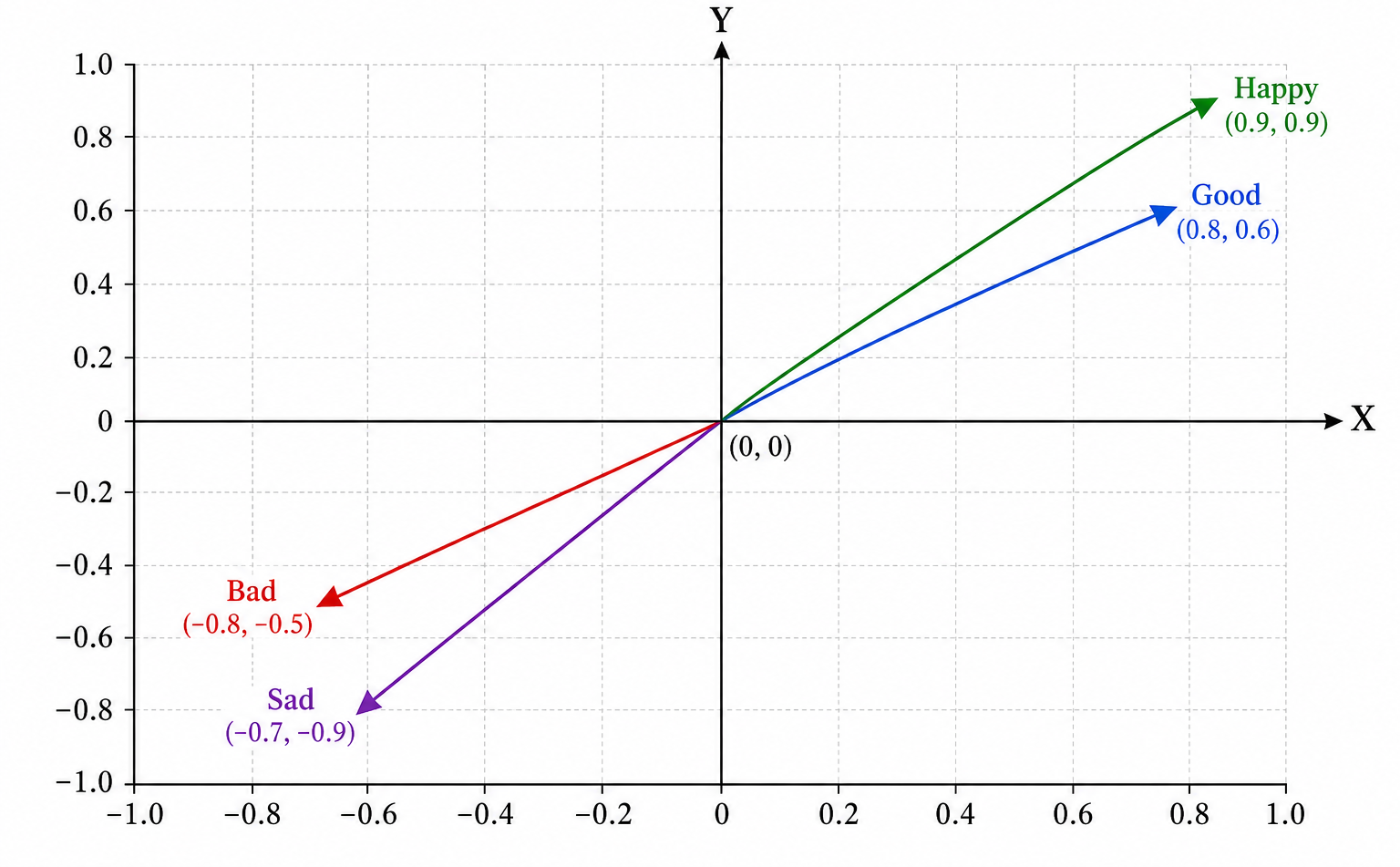
To make language understandable to a neural network, words are converted into vectors, which are simply lists of numbers. As shown above, words such as "good," "bad," "happy," and "sad" are represented by numerical vectors instead of plain text. These vectors place words in a high-dimensional mathematical space where words with similar meanings end up closer together and words with opposite meanings end up farther apart. The model learns these relationships automatically during training, allowing it to capture semantic meaning mathematically. This idea, known as word embeddings, was a major breakthrough because it gave computers a way to represent and reason about relationships between words rather than treating them as unrelated symbols.

The Vocabulary Problem
Once words could be represented mathematically, another challenge appeared: vocabulary size. English contains hundreds of thousands of words, and many words have multiple forms, such as "run", "running", "runner", and "runnable". If every word received its own token, the vocabulary would become extremely large, making training and storage much more expensive.
Character-Based Tokenization
One possible solution was to split text into individual characters. This greatly reduces vocabulary size because only letters, numbers, and symbols need to be stored. However, words become much longer sequences of characters, which increases computation and makes learning language relationships more difficult. Researchers needed a solution between full-word tokens and character-level tokens.
Subword Tokenization
The solution was subword Tokenization. Instead of treating words as complete units or breaking them into individual characters, words are split into reusable pieces. For example, playing can become play + ing, while unbelievable can become un + believe + able. This approach keeps the vocabulary manageable while still preserving meaning. Most modern LLMs use some form of subword Tokenization.
Byte Pair Encoding (BPE)
One of the most popular Tokenization methods is Byte Pair Encoding (BPE). The process starts with individual characters and repeatedly merges character pairs that appear frequently together. Over time, common patterns become complete tokens. This allows the vocabulary to be built automatically from real language usage rather than being manually designed.
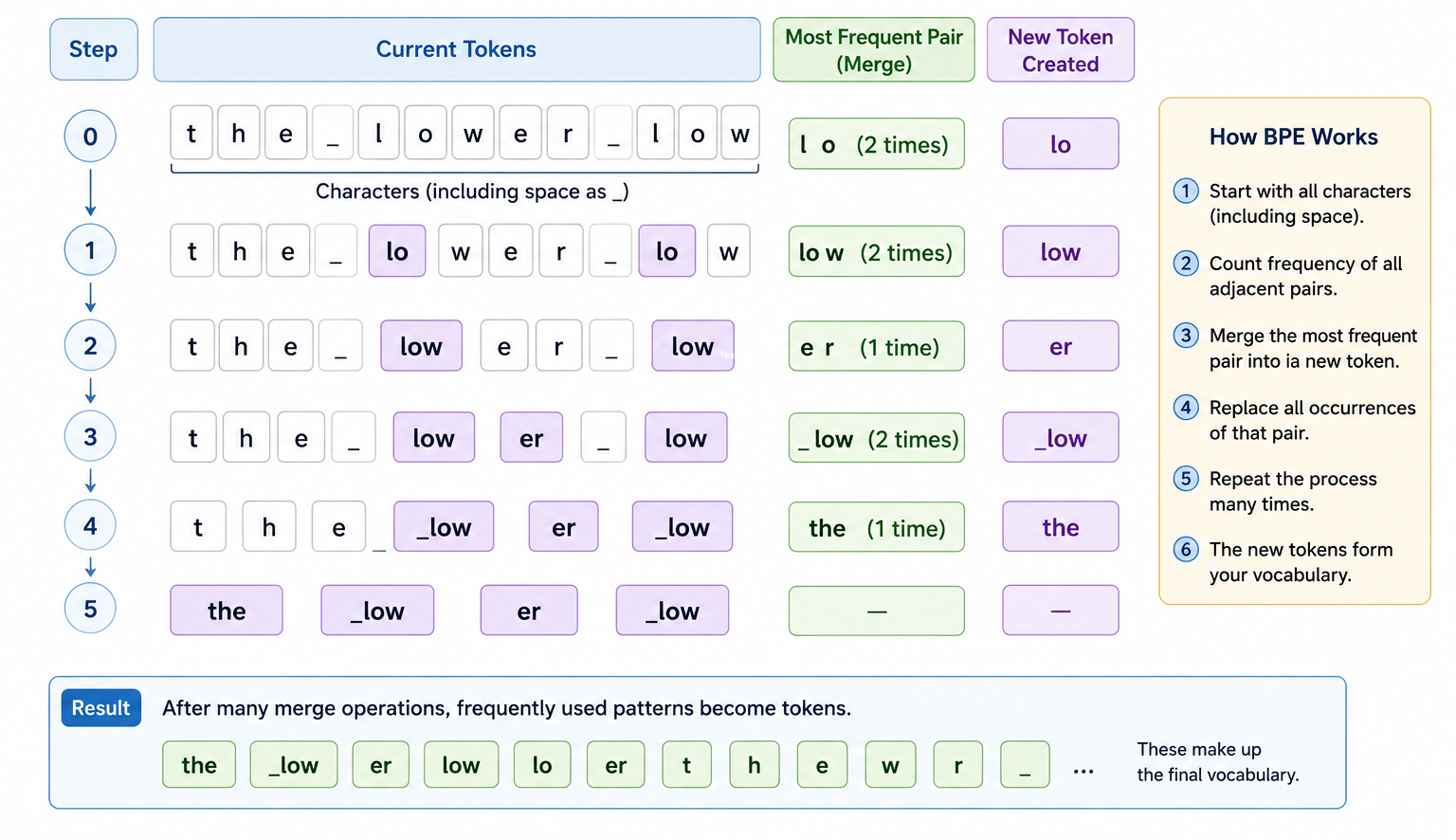
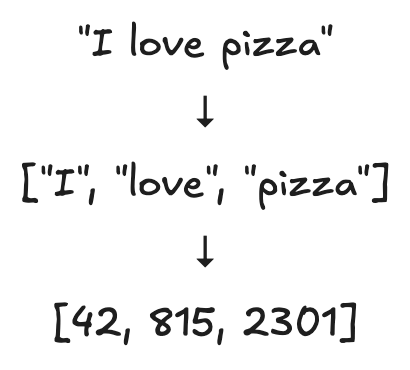
From Tokens to Token IDs
After Tokenization, each token is assigned a unique numerical identifier called a token ID. For example, a sentence such as "I love pizza" may be converted into a sequence of token IDs. These IDs allow text to be processed by computers efficiently, but by themselves they contain no meaning. The number assigned to a token is simply a label.
The Embedding Layer
Since token IDs do not carry meaning, they are passed through an embedding layer, which converts each token ID into a dense vector of numbers. This is where language is transformed into mathematics. Similar words tend to have similar embeddings, allowing the model to learn relationships between concepts. The transformer never works directly with words; it operates entirely on these embedding vectors.
The Transformer
The next stage is the Transformer, introduced in the 2017 paper Attention Is All You Need. The key innovation of the transformer is the attention mechanism, which allows tokens to focus on other relevant tokens in the sentence when determining meaning. For example, in the sentence:
The animal didn't cross the street because it was tired.
the model can learn that "it" refers to "animal" rather than "street" by paying attention to the surrounding context. This ability to capture relationships between words at different positions is one of the main reasons transformers became the foundation of modern LLMs.
Complete Text-to-Output Flow
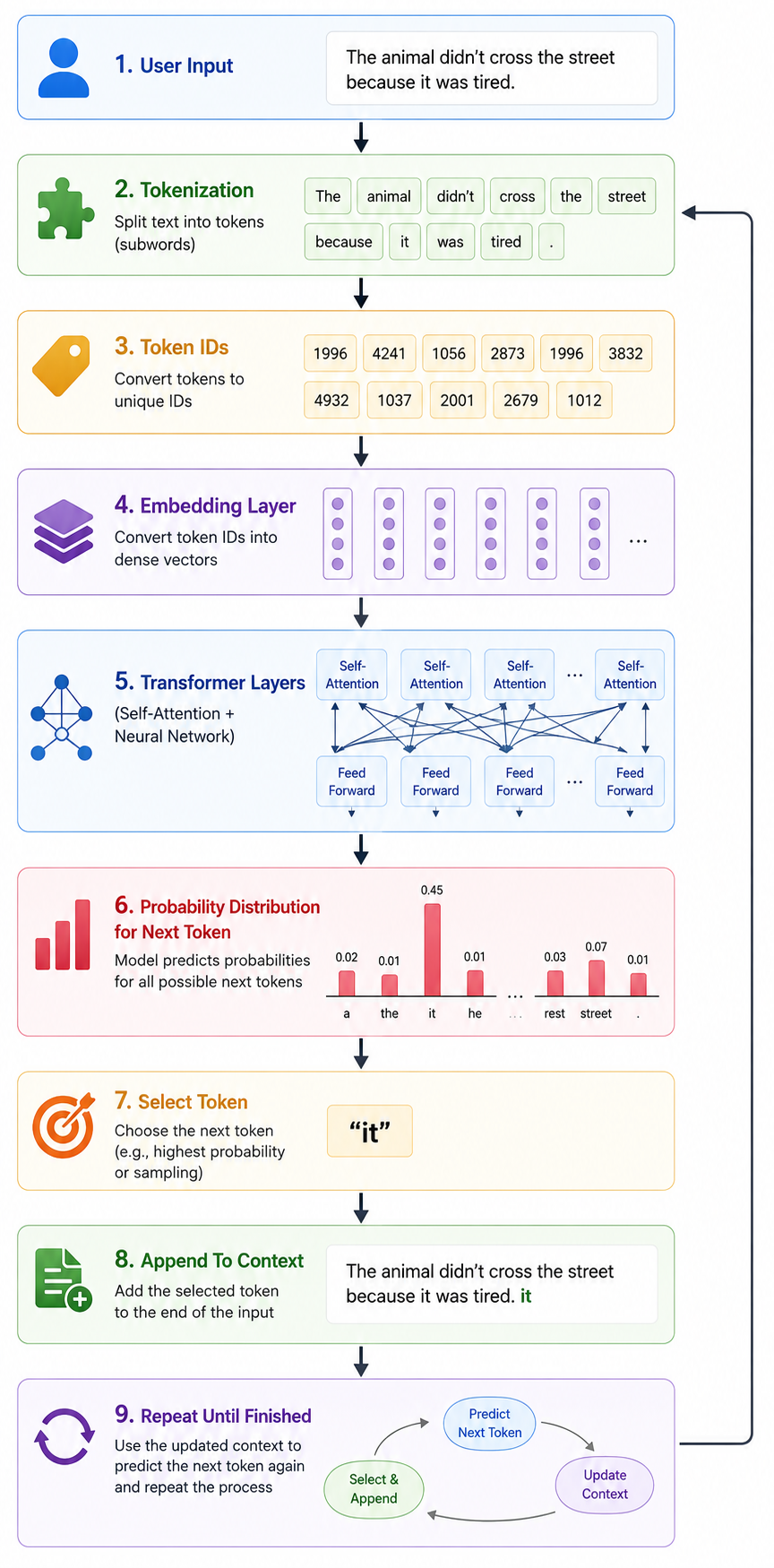
Why LLMs Seem Intelligent
Interestingly, the model was never explicitly taught:
- grammar
- coding
- reasoning
- translation
- summarization
It only learned to predict the next token.
Yet because it saw enormous amounts of text, many capabilities emerged naturally.
This phenomenon is called 'emergent behaviour'.
Limitations
Even though LLMs are powerful, they have important limitations.
Hallucinations
The model may generate information that sounds correct but is actually false.
Example:
- fake references
- fake URLs
- invented facts
The model optimises for likely text, not truth.
Bias
The model learns from human-generated data.
If the training data contains biases, the model may reproduce them.
Examples include:
- language bias
- cultural bias
- selection bias
- political bias
Common LLM Settings
Modern LLMs expose several settings that control how text is generated.
Temperature
Temperature controls randomness.
A low temperature makes the model choose the most likely next token more often, producing focused and predictable answers.
A high temperature increases randomness, making outputs more creative but sometimes less reliable.
Example: Use a low temperature for factual Q&A and a higher temperature for brainstorming or creative writing.
Top-P (Nucleus Sampling)
Top-P controls the pool of candidate tokens the model can choose from.
Instead of considering every possible token, the model keeps selecting tokens until their combined probability reaches the top-P value, then chooses from that smaller set.
Example: A lower Top-P produces more focused responses, while a higher Top-P allows more variety.
Max Length
Max length limits how many tokens the model can generate before stopping.
Example: Useful when generating summaries, short answers, or responses with strict length limits.
Stop Sequences
A stop sequence is a token or string that tells the model when to stop generating text.
Example: If the stop sequence is "11.", asking for a numbered list will cause generation to stop before item 11, producing only 10 items.
Frequency Penalty
Frequency penalty reduces the chance of repeatedly generating words that have already appeared many times.
The more often a token appears, the stronger the penalty becomes.
Example: Useful when the model keeps repeating the same phrases or keywords.
Presence Penalty
A presence penalty discourages reuse of tokens that have already appeared at least once.
Unlike a frequency penalty, the penalty does not increase with repeated occurrences.
Example: Useful for encouraging the model to introduce new topics or ideas instead of revisiting the same ones.
Prompt Engineering and Common Prompting Techniques
Now that we have gone through the core concepts of LLMs, let's talk about prompting. At its core, prompting is about influencing probabilities.
An LLM generates text by predicting the most likely next token. Every word, instruction, example, or piece of context you add to a prompt changes those probabilities. This is why even small changes in wording can sometimes produce very different outputs.
In general, the more relevant information you provide, the higher the probability that the model will generate the output you are looking for.
General Prompting Tips
A few simple practices usually improve results:
- Start with a clear and simple instruction.
- Use action words such as 'write', 'summarise', 'classify', 'translate', 'explain', or 'extract'.
- Separate instructions, context, input data, and expected output format.
- Be specific about what you want.
- Avoid adding unnecessary details that may confuse the model.
A common prompt structure looks like:
Instruction
------------
Context
------------
Input Data
------------
Expected Output FormatIn many cases, this simple structure is enough to get good results.
Common Prompting Techniques
Zero-Shot Prompting
Zero-shot prompting means giving the model only instructions without examples.
Example uses:
- Summarization
- Translation
- Text classification
- Explaining concepts
- Generating ideas
This works best when the task is straightforward and the model already understands what is being asked.
Few-Shot Prompting
Few-shot prompting provides a few examples before asking the model to solve a new problem.
The examples show the pattern that should be followed.
Example uses:
- Specific output formats
- Domain-specific tasks
- Unusual question styles
- Consistent response formatting
The model learns the pattern from the examples and continues it.
Chain of Thought (CoT)
Chain of Thought encourages the model to reason through multiple steps before reaching an answer.
Instead of jumping directly to a conclusion, the model breaks the problem into smaller reasoning steps.
Example uses:
- Mathematics
- Logic problems
- Planning
- Multi-step analysis
This technique is useful when solving the problem requires intermediate reasoning.
Self-Consistency
Self-consistency extends the chain of thought.
Instead of generating a single reasoning path, the model generates multiple independent reasoning paths internally and selects the answer that appears most consistently across them.
Example uses:
- Mathematical reasoning
- Competitive problem-solving
- Logic puzzles
- Scientific reasoning
This often improves accuracy on difficult reasoning tasks.
Tree of Thoughts (ToT)
Tree of Thoughts expands the idea further.
Instead of following one reasoning path, the model explores multiple possible paths, evaluates them, discards weak paths, and continues exploring promising ones.
You can think of it as a search algorithm operating over reasoning steps.
Example uses:
- Complex planning
- Strategy problems
- Product design
- Business decision-making
- Puzzle solving
Prompt Chaining
Prompt chaining breaks a large task into multiple smaller prompts.
The output of one prompt becomes the input of the next prompt.
Example:
Research → Summarize → Generate Report → Review Report
This often produces better results than asking the model to do everything in a single prompt.
RAG (Retrieval-Augmented Generation)
RAG provides external knowledge to the model before it generates an answer.
Instead of relying only on what was learned during training, the model retrieves relevant information from documents, databases, or knowledge bases.
Example uses:
- Company documentation
- Internal knowledge bases
- PDFs
- Product manuals
- Frequently changing information
This significantly reduces hallucinations when accurate source information is available.
Reflection and Critique Prompting
In this technique, the model reviews its own answer before producing a final response.
The model acts as its own reviewer and attempts to identify mistakes, missing information, or weak reasoning.
Example uses:
- Code review
- Report generation
- Research summaries
- Quality checking
Role Prompting
Role prompting assigns a role or perspective to the model.
Examples:
- "Act as a software architect."
This helps guide the style, vocabulary, and perspective of the response.
Final Thoughts
Prompt engineering is an iterative process rather than a fixed set of rules. Different models, model versions, and providers may respond differently to the same prompt.
A technique that works well today may become less important as models improve. Modern LLMs are becoming increasingly good at understanding user intent, which means many tasks now require much less prompt engineering than they did a few years ago.
However, the core idea remains the same:
Every word added to a prompt changes the probability distribution of the next generated token. Prompt engineering is ultimately the art of shaping those probabilities to guide the model toward the desired output.
My Thoughts on LLMs and Understanding
One debate that comes up often is whether LLMs actually understand things or whether they are simply doing very advanced pattern matching.
Personally, I lean more toward the pattern-matching side.
The interesting thing is that the results often look like understanding. The model can answer questions, explain concepts, write code, summarise documents, and even reason through problems. From the outside, it feels like understanding because the outputs are often correct and useful.
But when I look at how these systems are trained, it still feels like a very sophisticated form of pattern matching. They have seen enormous amounts of data and learned relationships between tokens, concepts, and ideas. When we ask a question, they generate an answer based on those learned patterns.
At the same time, I don't have complete confidence in that opinion.
Human intelligence evolved over billions of years. The human brain is the result of an incredibly long process of evolution. If humans are able to create something with human-like reasoning or learning capabilities in just a few decades, that would be a remarkable achievement. Sometimes it feels difficult to believe that we have already recreated something comparable to human understanding.
I also wonder whether humans themselves are doing something that is not completely different. We are constantly predicting. We predict what people mean, what might happen next, what words to say, and what actions to take. In some sense, human thinking also looks like a prediction process that never completely stops.
If one day we create AI that truly thinks like a human, I suspect it may inherit some of the same limitations that humans have.
Humans need rest. Humans consume energy. Humans cannot think forever without fatigue. Humans forget things. Humans need resources to survive.
If future AI systems develop intelligence that is much closer to human intelligence, I wonder whether similar constraints will appear in some form. Maybe they will need downtime, energy, memory management, or other limitations that resemble human needs.
And if we eventually reproduce every important aspect of human intelligence, then an interesting question appears:
What was the point of building it if we ended up recreating many of the same limitations?
I don't know the answer.
What I do know is that LLMs are one of the most interesting technologies I have ever learned about. Their capabilities are already impressive, and the pace of improvement is surprisingly fast.
The future of AI feels both exciting and uncertain. It is difficult to predict where these systems will be in five, ten, or twenty years. For now, I think the most honest answer is that we are still figuring out what intelligence really is, and that makes the future hard to predict.